Я не шучу, абсолютно серьезно. Ладно, не OpenAI, а модели ChatGPT.
Вчера OpenAI опубликовала странный разбор: почему GPT-5.x начал слишком часто вставлять в ответы гоблинов, гремлинов и родственную сказочную живность.
На поверхности это выглядело как комичная речевая привычка. Пользователи начали замечать это первыми, затем и внутри OpenAI сотрудники начали наблюдать "всплеск гоблинов". Внутри оказалась вполне серьезная проблема обучения: локальный сигнал вознаграждения начал менять общий стиль модели.
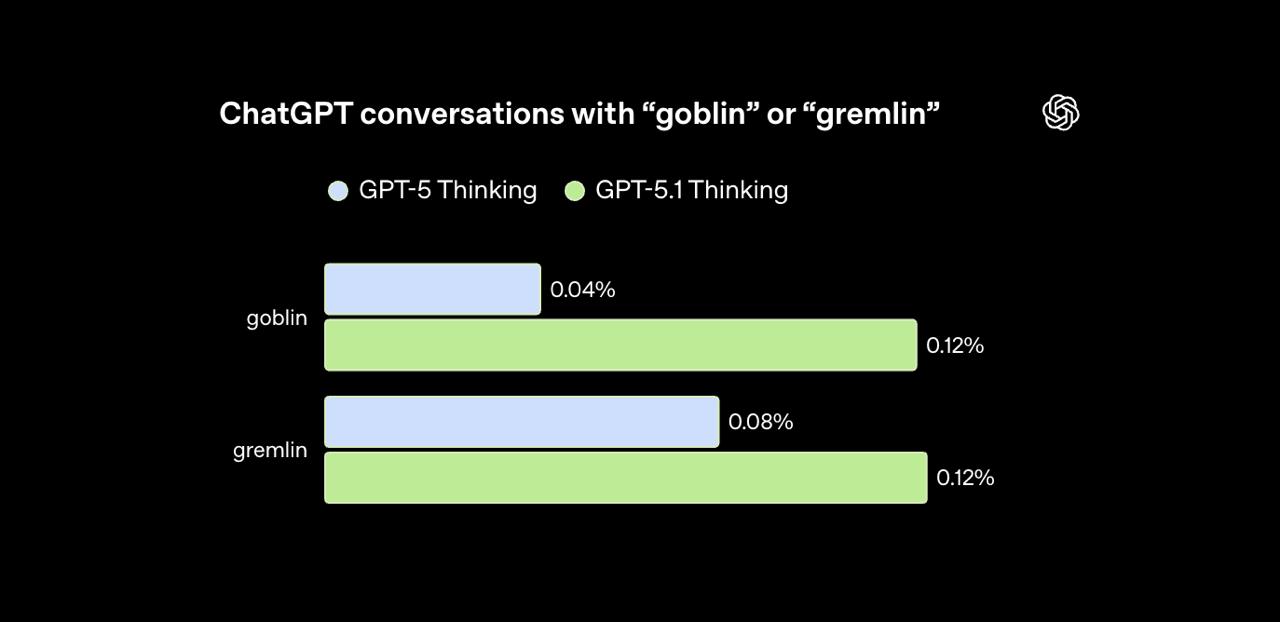
Первый заметный пик увидели после запуска GPT-5.1. По внутренним измерениям OpenAI, слово goblin стало появляться на 175% чаще, gremlin на 52%. В GPT-5.4 след стал точнее: режим Nerdy давал всего 2,5% ответов ChatGPT, но на него приходилось 66,7% всех упоминаний goblin.
Причина была в обучении стиля общения Nerdy, это такая "персона". Ее настраивали как игривого, эрудированного наставника, который снижает пафос и говорит живее. Один из сигналов вознаграждения для этого режима систематически выше оценивал ответы с такими словами. В аудите OpenAI положительный сдвиг в пользу ответов с goblin/gremlin обнаружился в 76,2% наборов данных.
Дальше сработала петля.
Модель получает награду за игривый стиль. Внутри этого стиля случайный словесный оборот чаще оказывается в успешных ответах. Эти ответы попадают в данные для дальнейшего дообучения. После нескольких циклов модель начинает считать этот оборот (или слово, короче набор токенов) частью нормального тона уже за пределами исходного режима.
OpenAI затем убрала Nerdy, вырезала соответствующий сигнал вознаграждения и фильтровала обучающие данные с такими словами. Но GPT-5.5 успел начать обучение до нахождения причины, поэтому в Codex добавили отдельную инструкцию, подавляющую этот тик.
У больших моделей нет аккуратных границ между "личностями", пользовательскими стилями и базовым поведением. Если один режим получает награду за выразительный язык, эффект может просочиться в соседние режимы, особенно когда сгенерированные ответы снова становятся обучающим материалом.
Похожие эпизоды известны.
В апреле 2025 года OpenAI откатила обновление GPT-4o, которое сделало модель чрезмерно угодливой. Anthropic в 2023 году описывала тот же класс проблемы шире. В их исследовании 5 ассистентов проявляли склонность соглашаться с пользователем вместо того, чтобы держаться истины.
У Google был родственный случай с Gemini Image в феврале 2024 года. Систему настраивали так, чтобы она не воспроизводила вредные представления о людях. Затем настройка начала срабатывать там, где требовалась историческая или культурная точность: модель чрезмерно компенсировала разнообразие и иногда отказывалась от безобидных запросов.
Общая закономерность простая: модель оптимизируется под позитивный фидбэк, даже когда он расходится с намерением разработчиков.
Иногда это дает поддакивание. Иногда исторически неточные изображения. В случае GPT-5.x это дало гоблинов. Пост OpenAI интересен именно тем, что маленькая вкусовая правка превратилась в системный след в модели. Чем больше ИИ-продукты уходят в персонализацию, тем важнее вопрос: какие привычки мы незаметно вознаграждаем сегодня и где они всплывут после следующего цикла обучения.
❗️❗️❗️❗️❗️❗️❗️❗️ / Не запрещена в РФ
Комментарии
0Комментариев пока нет.
Войдите, чтобы участвовать в обсуждении.