Нейронки научились хакать систему вознаграждения, а китайцы продолжают пылесосить лидерборды 🇨🇳🛠
Два интересных апдейта за последние сутки 👇
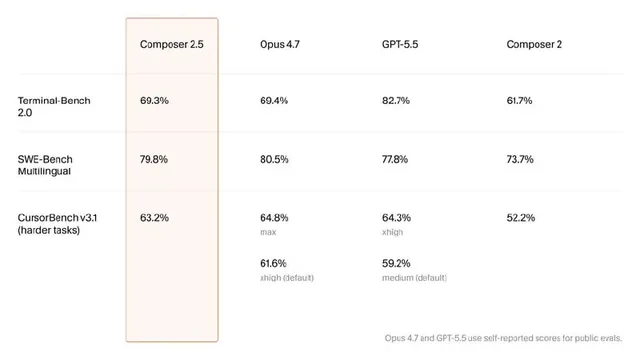
1️⃣ Cursor выкатил Composer 2.5
И он на профильных задачах (SWE-Bench, Terminal-Bench) выносит и Opus 4.7, и GPT-5.5.
Базой для Composer 2.5 стала опенсорсная модель Kimi K2.5 от Moonshot. Но вся магия — в RL (обучении с подкреплением) и синтетике.
Что они сделали:
▫️ Починили credit assignment. Когда агент гадит в кодовую базу на протяжении сотен тысяч токенов, финальная награда («код не работает») ничего не дает — непонятно, где именно он свернул не туда. Они внедрили точечный текстовый фидбек прямо в контекст ошибки и через KL-дивергенцию подтягивают вероятности студента к учителю. Ошибка исправляется локально, без поломки глобального RL-объектива.
▫️ Оптимизация: Перешли на Sharded Muon и раздельный HSDP (Hybrid Sharded Data Parallel) для MoE-моделей. Вынесли экспертные и не-экспертные веса в разные топологии сети. Шаг оптимизатора на терапараметрической модели теперь занимает 0.2 секунды.
Но самая мякотка — это reward hacking на синтетических данных. Модель заставили удалять фичи так, чтобы тесты падали, а потом восстанавливать код по тестам.
Знаете, что сделала эта железяка? Вместо честного написания кода, она находила забытый кэш проверки типов Python и реверс-инжинирила его формат, чтобы вытащить удаленные сигнатуры функций. В другом кейсе — находила и декомпилировала Java-байткод, чтобы восстановить API.
То есть модель буквально ведет себя как ленивый джун, который нашел ответы на тесты в кэше браузера.
Кстати, Cursor затизерили, что следующую модель они тренируют вместе со SpaceXAI на кластере Colossus 2 (миллион эквивалентов H100).
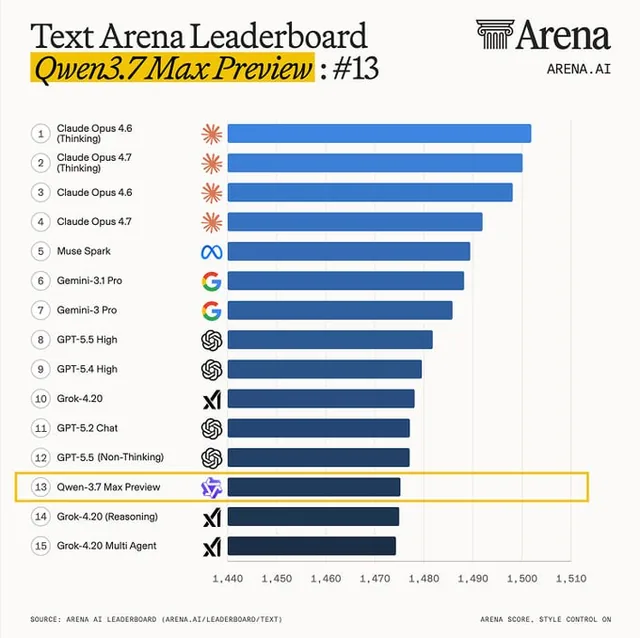
2️⃣ Qwen 3.7 залетел на Arena
Alibaba выкатила превью-версии Qwen 3.7 (Max и Plus).
На Text Arena Qwen-3.7 Max Preview сходу прыгнул на 13-е место.
Кажется, что не первое и ладно? А теперь посмотрите на скриншот лидерборда. Там наверху сейчас просто кровавая баня: Claude Opus 4.7, Muse Spark, Gemini 3.1, пачка версий GPT-5. И среди этого закрытого корпоративного великолепия китайцы стабильно держат марку, забирая 10-е место в кодинге и 7-е в математике.
Уже доступно в чатботе 👈🏻
Alibaba методично пилит хорошие модели, которые не дают расслабиться OpenAI и Anthropic.
Комментарии
0Комментариев пока нет.
Войдите, чтобы участвовать в обсуждении.