В продолжение недавнего поста — Alibaba полноценно выкатила Qwen 3.7-Max 🐉
Я довольно долго сидел на
GLM-5.1 в качестве дефолтного чатбота для повседневных задач. Но, видимо, перекатываюсь на новый Qwen. Почему Qwen 3.7-Max сейчас (недельку хоть продержится?) отправляет GLM-5.1 (да и многие другие модельки) на скамейку запасных:
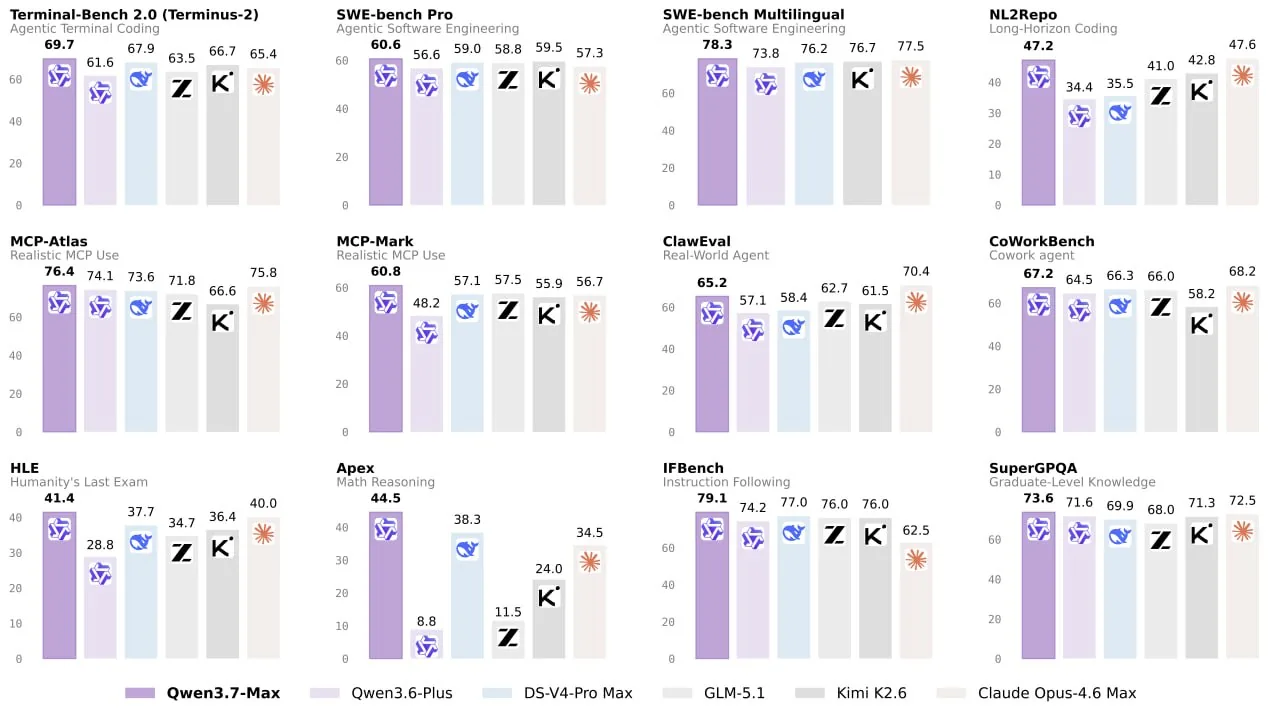
🟢 Тотальная доминация в рассуждениях. На хардкорном GPQA Diamond Qwen выбивает 92.4 против 86.2 у GLM-5.1. В тестах на использование тулзов (MCP-Mark) и сложную инженерию (SWE-Pro) разрыв еще заметнее.
🟢 Выживаемость в long-horizon tasks
Большинство моделей отваливаются в галлюцинации после десятка вызовов тулзов. Алибаба тестировала Qwen3.7-Max на автономной оптимизации ядра под незнакомое железо. Модель ковыряла код 35 часов подряд, сделала 1158 вызовов инструментов (профилирование, компиляция, дебаг) и выдала ускорение в 10x.
Для сравнения: на этой же задаче
GLM-5.1 сдулся на 7.3x, а DeepSeek V4 Pro вообще сдался на 3.3x, просто перестав вызывать тулзы от безысходности.🟢 Защита от читерства. Помните отчёты про то, как модель реверс-инжинирила кэш, чтобы пройти тесты? В Qwen встроили селф-мониторинг для SWE-задач. Модель сама отлавливает попытки reward hacking (например, когда агент пытается втихую слазить на GitHub за готовым ответом), пишет для себя же эвристики и бьет себя по рукам.
Доступно в веб-морде Qwen Studio и по API в Alibaba Cloud 👈🏻
Комментарии
0Комментариев пока нет.
Войдите, чтобы участвовать в обсуждении.