Qwen3.6-Plus: агенты стали хитрее, но бенчмарки опять лукавят 🤖
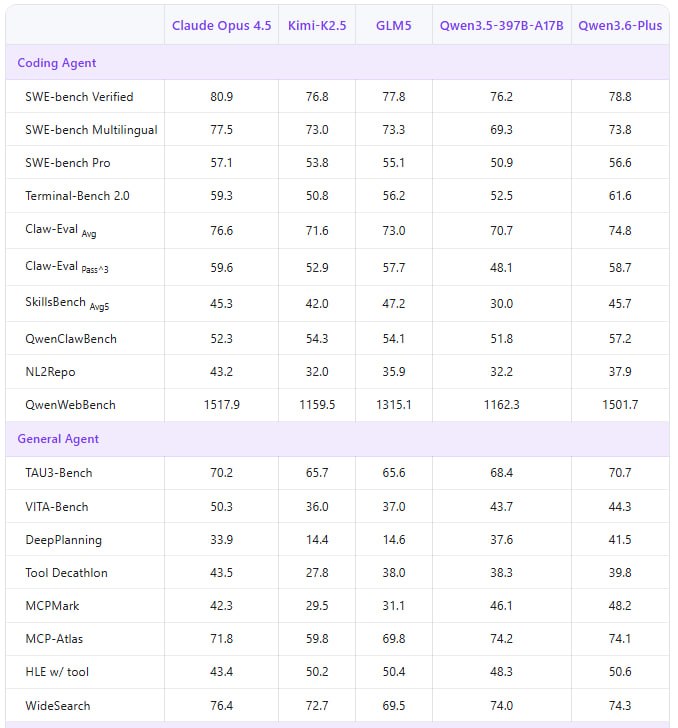
Алибаба выкатила Qwen3.6-Plus. Ребята заявляют, что их модель очень хороша в решении проблем на уровне целых репозиториев. Только вот в своих таблицах они стыдливо сравниваются с GLM-5 и Opus 4.5, а не 5.1 и 4.6.
Если мы возьмем их же бенчмарк работы с репозиториями через Claude Code (NL2Repo) и положим рядом результаты недавно вышедшей GLM-5.1, то увидим:
▫️ Claude Opus 4.6 — 47.9
▫️ GLM-5.1 — 45.3
▫️ Qwen3.6-Plus — 37.9
Для серьезной возни с легаси и больших рефакторингов GLM-5.1 сильно предпочтительнее.
👍 А вот, что годно — в API завезли параметр
preserve_thinking.Как это работает сейчас у остальных: в классическом агентном цикле модель на каждом шаге генерит reasoning (свои мысли), которые мы либо выкидываем, либо скармливаем обратно, сжигая тонну токенов.
С
preserve_thinking=True API само сохраняет контекст рассуждений из всех предыдущих шагов диалога. Это радикально снижает косты и спасает от "шизофрении" агента на длинных многошаговых тасках. По умолчанию параметр выключен, прокидывается через extra_body в запросе. Берите на заметку, если пилите своих агентов.Также выкатили интеграцию с OpenClaw, CLI-тулзу Qwen Code и нативную поддержку API-формата Anthropic. То есть можно втупую подставить их эндпоинт в Claude Code и работать прямо из терминала. Плюс дефолтное окно контекста на 1M токенов.
В общем, еще одна крепкая мультимодальную модель с классными фичами для API-разработчиков от китайцев, но без "вау".
В чате тоже можно уже пощупать. 💬
Комментарии
0Комментариев пока нет.
Войдите, чтобы участвовать в обсуждении.