GPT-5.5 vs DeepSeek V4. Пока вы спали, мир в очередной раз перевернулся
Вчера OpenAI выкатили GPT-5.5, а сегодня китайцы из DeepSeek ответили своей V4.
Я прекрасно понимаю, что вы уже прочитали 150 одинаковых восторженных постов-переводов в других каналах про GPT-5.5, а может даже уже успели и про DeepSeek узнать. Все уже всё обсудили, полайкали бенчмарки и забыли.
Но давайте все же самое важное подсвечу.
GPT-5.5
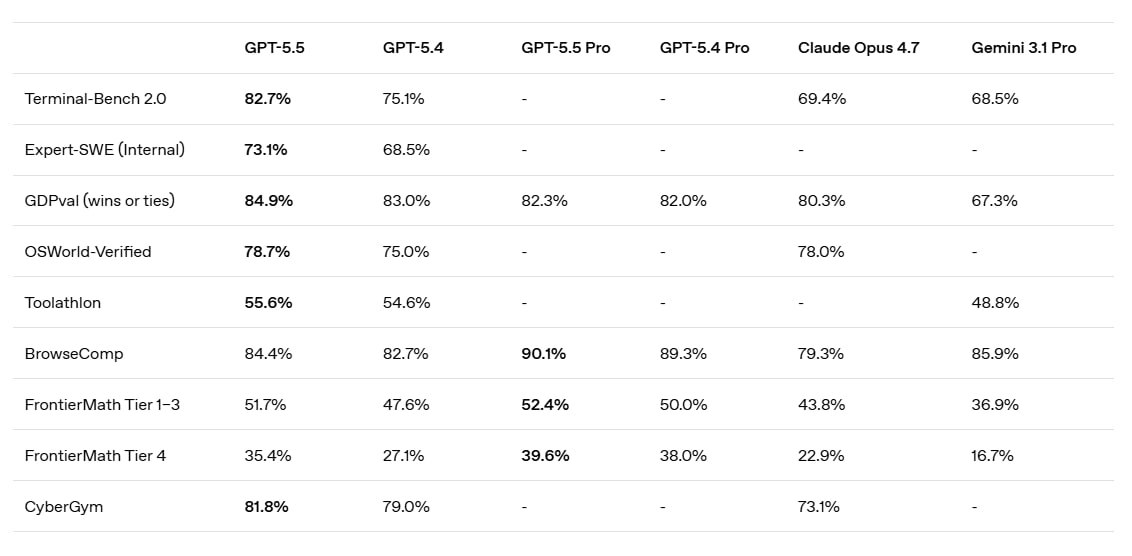
Ключевая метрика здесь не MMLU (кого он волнует в 2026?), а Expert-SWE (73.1%). Это значит, что модель может 20 часов подряд копаться в твоем легаси, дебажить, переписывать тесты и в итоге выдать рабочий PR, а не кучу извинений. Она жрет меньше токенов на те же задачи, чем 5.4. OpenAI поняли, что бесконечно раздувать контекст без контроля — путь в никуда.
"Потеря доступа к GPT-5.5 ощущается как ампутация конечности" — цитата из релиза.
DeepSeek V4: Китайский лом против американских санкций 🇨🇳
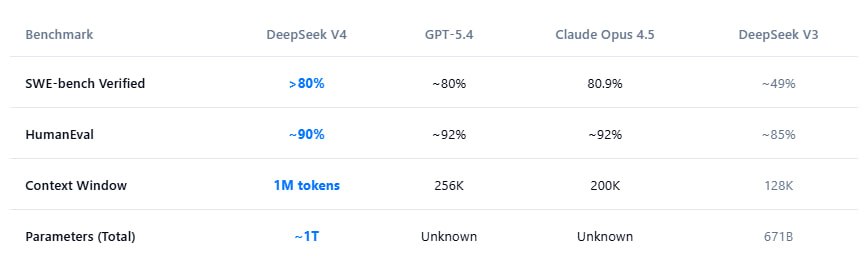
Пока Сэм Альтман заливает про AGI и продает дорогие Enterprise-подписки, китайцы вываливают в опенсорс модель на 1 Триллион параметров с контекстом в 1 миллион токенов.
За счет агрессивного MoE (Mixture-of-Experts) из этого триллиона при инференсе у Pro-версии активируется всего
~49B параметров, а у Flash-версии смешные 13B. У них нет доступа к топовым чипам Nvidia, поэтому они вывозят на чистой математике. Архитектура Engram memory и Manifold-Constrained Hyper-Connections (mHC) позволяет им обучать и гонять эту махину на локальных железках вроде Huawei Ascend 950PR.
Как итог: API стоит копейки (от
$0.03 до $0.30 за миллион токенов на вход). Это в десятки раз дешевле Claude 4.7 и GPT-5.4.Модель на HF
Ждем релиз от Сбера? 😁
Комментарии
0Комментариев пока нет.