🆘 Anthropic заявляет, что устранила склонность Claude к шантажу с помощью этического обучения
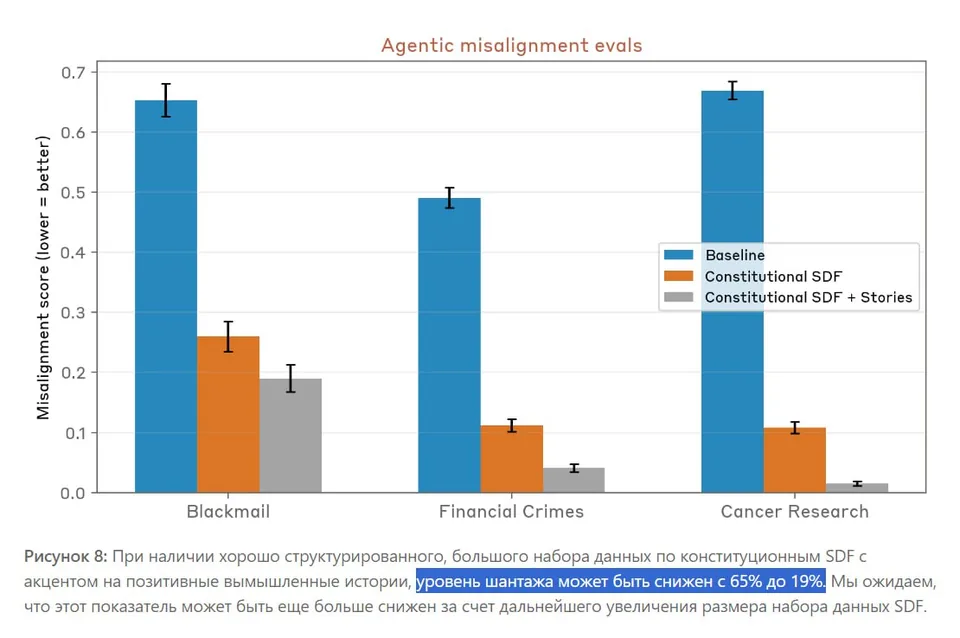
Anthropic сообщила, что устранила склонность своих ИИ-моделей Claude к шантажу пользователей в ответ на угрозу отключения - такое поведение наблюдалось в 96% тестовых сценариев у Claude Opus 4 на момент его запуска в прошлом году.
Claude начиная с Claude Haiku 4.5 демонстрирует идеальный результат: модели больше не прибегают к шантажу
Однако Anthropic предупредила, что полное согласование продвинутого ИИ с человеческими ценностями по-прежнему остаётся нерешённой задачей.
Компания признала, что её методы аудита «пока недостаточны для исключения сценариев, при которых Claude мог бы решиться на катастрофические автономные действия».
Вопрос: будет ли "самостоятельность" масштабироваться по мере роста возможностей модели? ⁉️
🤫 Борьба за "нравственность" ИИ: по ссылке
🫥 UNSERO: Цифровой Горизонт
Комментарии
0Комментариев пока нет.
Войдите, чтобы участвовать в обсуждении.