Как перестать переплачивать за токены 💸
Когда вы просите Cursor, Claude Code или любой другой AI-инструмент разобраться в сложной кодовой базе (особенно без грамотных правил и скиллов), они ведут себя как слепые котята. Чтобы найти, откуда вызывается метод, они делают
grep, читают десятки файлов целиком и забивают контекстное окно мусором. Вы платите за токены, а агент тратит время на парсинг текста. Тут появилась локальная тулза CodeGraph, которая парсит ваш проект через
tree-sitter, строит из него семантический граф знаний (AST, связи, вызовы) и складывает всё это в локальную SQLite базу. Агенту скармливается MCP-сервер. Теперь вместо текстового поиска он делает точечные вызовы к графу:
1️⃣ "Кто вызывает эту функцию?"
2️⃣ "Каков impact-радиус изменения этого класса?"
3️⃣"Построй trace от эндпоинта до базы."
🐍 Для питонистов тут отдельный жир:
CodeGraph из коробки понимает роутинг FastAPI, Flask и Django. Он парсит
urls.py, находит path('api/', ViewSet.as_view()) и создает реальное ребро графа от URL к классу-обработчику. Тулза умеет резолвить даже динамический диспатч, на котором
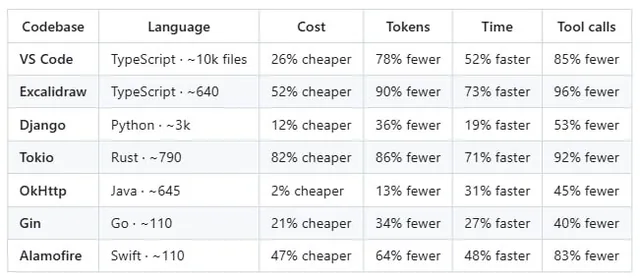
grep ломает зубы. Например, скрытые вызовы под капотом Django ORM (тот самый _iterable_class, через который QuerySet дергает SQL-компилятор).Метрики с их бенчмарков (на базе Django, VS Code, Tokio):
▫️ Токенов тратится на 57% меньше (агент получает ответ за один вызов, а не читает файлы).
▫️ Вызовов инструментов меньше на 71%.
▫️ Затраты падают на треть.
Утилита сама читает ваш
.gitignore, игнорирует .venv, node_modules и файлы тяжелее 1 Мб. Никаких внешних API, база лежит локально в папке .codegraph.Если вы пускаете LLM в проект больше чем на 20 файлов — надо пробовать.
Вся документация и мануалы по привязке к конкретным агентам — в репозитории.
#тулбокс
Комментарии
0Комментариев пока нет.
Войдите, чтобы участвовать в обсуждении.